原文地址: https://developers.google.cn/machine-learning/problem-framing (opens new window) , https://developers.google.cn/machine-learning/problem-framing/cases (opens new window)
# 简介
欢迎来到机器学习-寻找合适的问题章节! 本课程可帮助您了解哪些问题可以使用机器学习 (ML) 来解决. 本课程不涉及如何实现 ML 或处理数据.
# 学习目标
- 了解常见的 ML 术语
- 描述使用了 ML 的产品示例, 以及它们是如何使用 ML 来解决问题的
- 决定是否使用 ML 来解决问题
- 将 ML 与其他编程方法进行比较
- 将假设检验和科学方法应用于机器学习问题
 本课程适合初次接触机械学习的人.
本课程适合初次接触机械学习的人.
# 常见的机器学习问题
ML 是训练软件(称为 模型 Model)使用现有的数据集做出有用预测的过程. 训练完成后, 这个预测模型就可以用于对未曾见过数据进行预测. 然后我们便可以在产品使用这些预测: 例如, 系统预测用户会喜欢某个视频, 因此系统向用户推荐该视频.
通常, 人们将 ML 称为有两种范式, 监督学习和无监督学习. 然而, 将 ML 问题描述为属于监督学习和无监督学习之间的监督范围更为准确. 为简单起见, 本课程将重点介绍这两种极端情况.
# 什么是监督学习?
监督学习是一种机器学习方式, 训练模型时使用的是有标记 (Label)的训练数据.
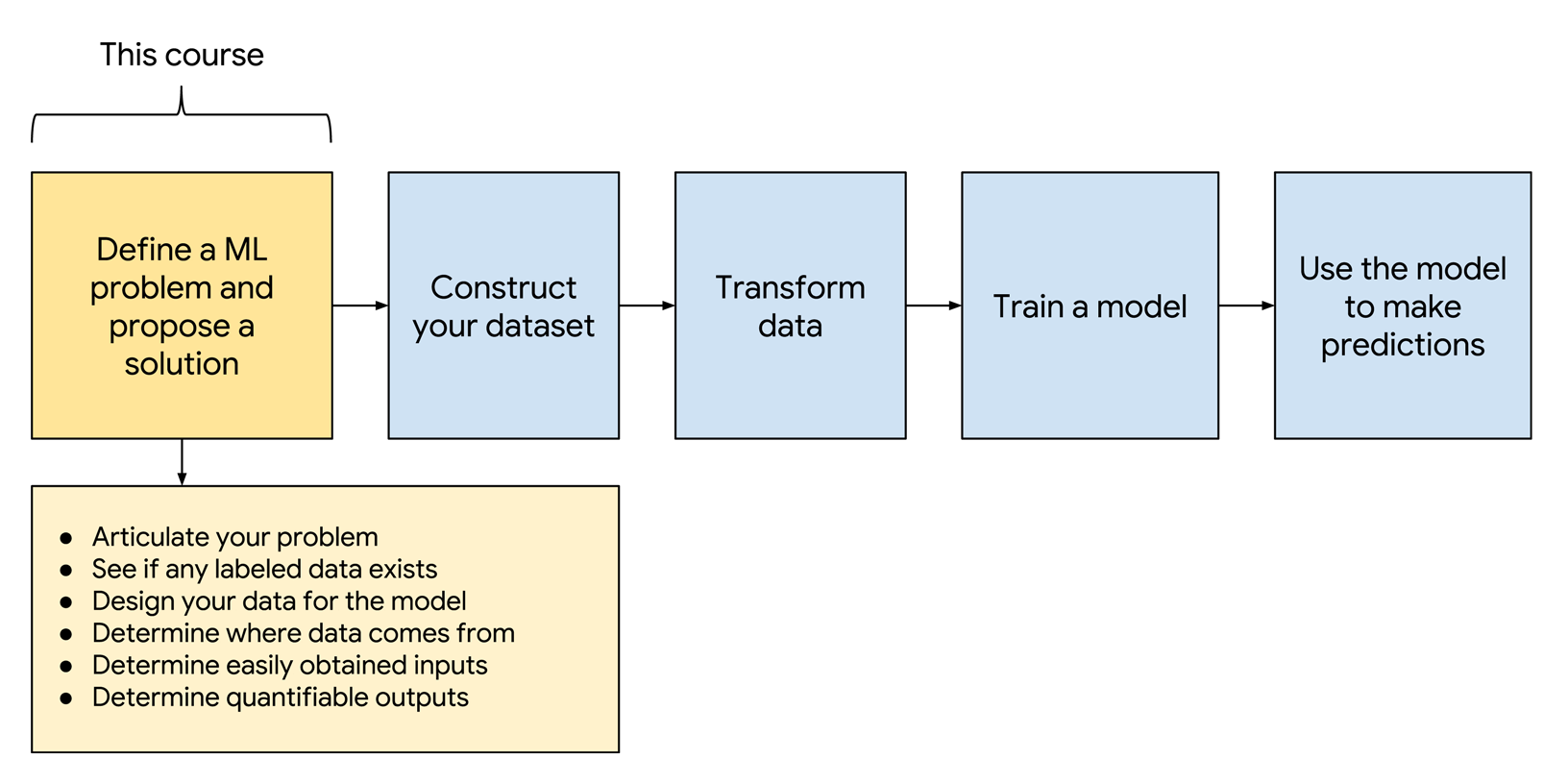
例如, 假设您是一名业余植物学家, 决心区分小人国植物属的两个物种(一种完全虚构的植物). 这两个物种看起来非常相似. 幸运的是, 一位植物学家汇总了她在野外发现的小人国植物及其物种名称的数据集.
以下是数据集中的一部分:
| 叶面宽度 | 叶面长度 | 物种 |
|---|---|---|
| 2.7 | 4.9 | 小叶种 |
| 3.2 | 5.5 | 大叶种 |
| 2.9 | 5.1 | 小叶种 |
| 3.4 | 6.8 | 大叶种 |
叶宽和叶长是 特征 (feature)(这就是下图将这两个维度都标记为 X 的原因), 而物种是标签. 一个真实的植物数据集可能包含更多的特征(包括对花朵的描述、开花时间、叶子的排列), 但仍然只有一个标签.
特征是测量或描述;标签本质上是“答案”. 例如, 数据集的目标是帮助其他植物学家回答 “这种植物是哪个物种?”的问题.
该数据集仅包含四个示例. 现实生活中的数据集可能会包含更多示例.
假设我们在坐标系上绘制叶子宽度和叶子长度的数据, 然后对物种进行颜色编码.
 在有监督的机器学习中, 您将特征及其相应的标签输入到一个称为 训练 的算法中. 在训练过程中, 算法逐渐确定特征与其对应标签之间的关系. 这种关系称为 模型. 在机器学习中, 模型通常非常复杂.
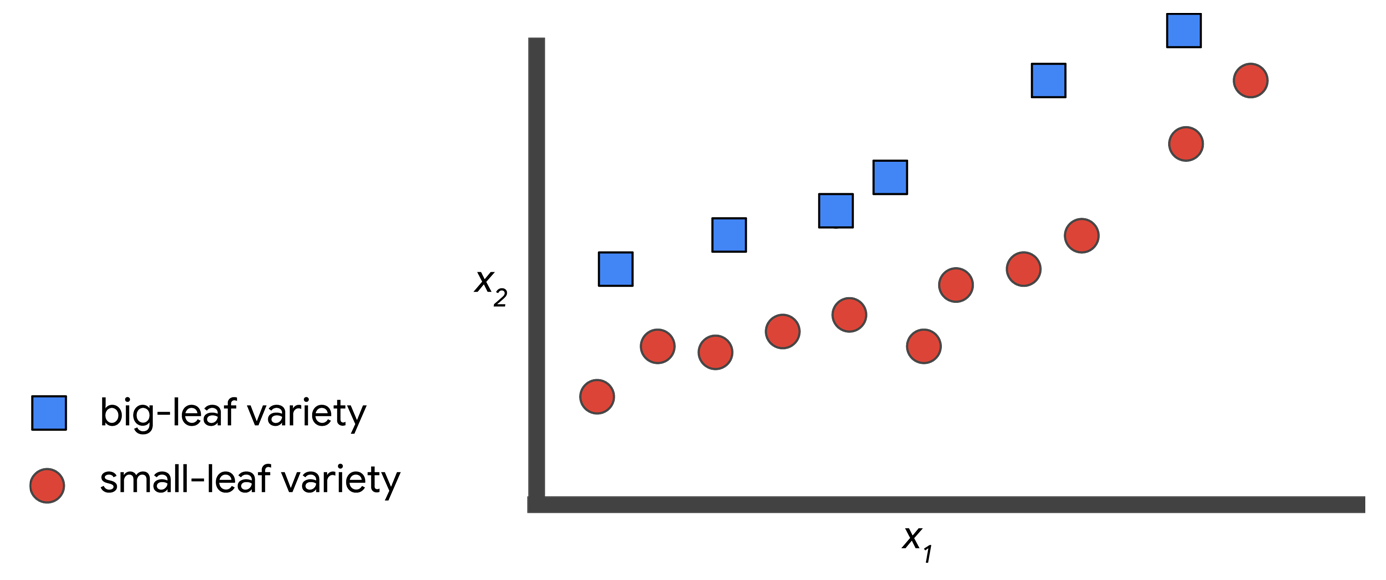
现在, 我们假设这个模型可以表示为一条分隔大叶和小叶的线:
在有监督的机器学习中, 您将特征及其相应的标签输入到一个称为 训练 的算法中. 在训练过程中, 算法逐渐确定特征与其对应标签之间的关系. 这种关系称为 模型. 在机器学习中, 模型通常非常复杂.
现在, 我们假设这个模型可以表示为一条分隔大叶和小叶的线:
 现在, 您应当可以使用该模型对丛林中发现的新植物进行分类了. 例如:
现在, 您应当可以使用该模型对丛林中发现的新植物进行分类了. 例如:
 为了将这一切联系在一起, 有监督的机器学习会在数据和标签之间找到可以用数学方法表示为函数的模式(pattern).
为了将这一切联系在一起, 有监督的机器学习会在数据和标签之间找到可以用数学方法表示为函数的模式(pattern).
**对于给定的一个输入特征, 你告诉系统预期的输出标签是什么, 因此你正在监督训练过程. ** ML 系统将学习这种标记数据的方式, 并在将来使用这种方式对训练期间未看到过的数据进行预测.
一个令人兴奋的监督学习的示例是 斯坦福大学的一项研究 (opens new window), 该研究使用模型检测图像中的皮肤癌. 在这种情况下, 训练集包含皮肤科医生标记为患有多种疾病之一的皮肤图像. ML 系统从其训练集中找到指示每种疾病的信号, 并使用这些信号对新的、未标记的图像进行预测.
# 什么是无监督学习?
无监督学习的目标是识别数据中有意义的模式. 为此, 机器必须从未标记的数据集中进行学习. 换句话说, 模型没有提示如何对每条数据进行分类, 并且必须推断出它自己的规则.
在下图中, 所有示例的形状都相同, 因为我们没有标签来区分此处的一种或另一种示例:
 将一条线拟合到未标记的点附近对我们并没有帮助: 我们仍然会在线条的两侧得到相同形状的示例.
显然, 我们将不得不尝试不同的方法.
将一条线拟合到未标记的点附近对我们并没有帮助: 我们仍然会在线条的两侧得到相同形状的示例.
显然, 我们将不得不尝试不同的方法.
 现在我们将这些数据划分为两个集群. (请注意, 集群的数量是任意的). 这些集群代表什么?这很难说. 有时, 模型会在数据中找到您不希望它学习的模式, 例如刻板印象或偏见.
现在我们将这些数据划分为两个集群. (请注意, 集群的数量是任意的). 这些集群代表什么?这很难说. 有时, 模型会在数据中找到您不希望它学习的模式, 例如刻板印象或偏见.
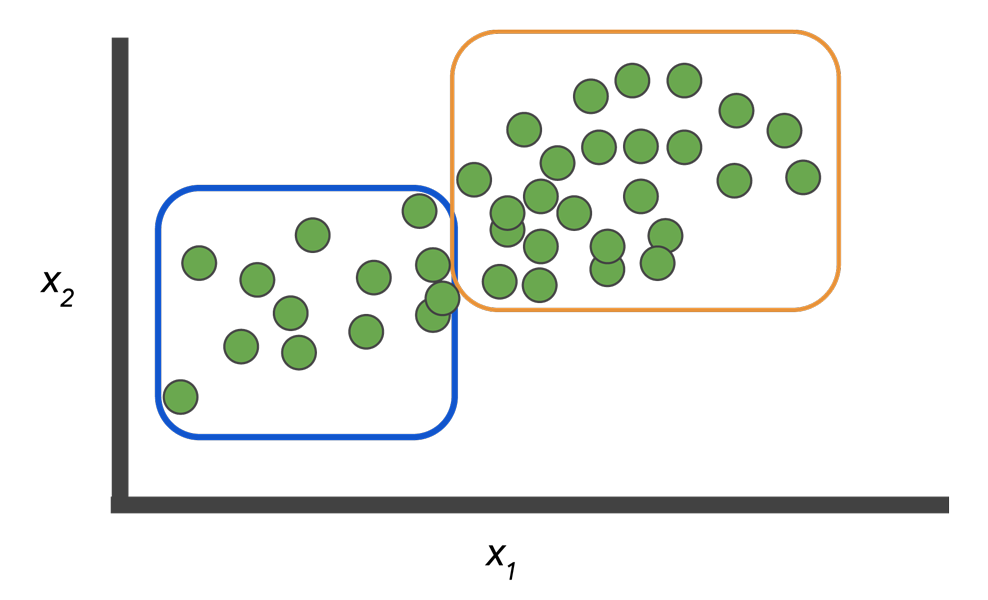 当新数据适合一个已知的集群时, 我们可以很容易地对其进行分类. 但是, 如果您的照片聚类模型以前从未见过穿山甲怎么办?系统会将新照片与犰狳或刺猬聚集在一起吗?本课程稍后将更多地讨论未标记数据和聚类的困难.
当新数据适合一个已知的集群时, 我们可以很容易地对其进行分类. 但是, 如果您的照片聚类模型以前从未见过穿山甲怎么办?系统会将新照片与犰狳或刺猬聚集在一起吗?本课程稍后将更多地讨论未标记数据和聚类的困难.
强化学习 机器学习的另一个分支是 强化学习 (RL). 强化学习不同于其他类型的机器学习. 在 RL 中, 您不会收集带有标签的示例. 你可以想象一下你想教一台机器玩一个非常简单的视频游戏并且永远不会输. 您使用游戏设置模型(在 RL 中通常称为代理), 并告诉模型不要出现 “游戏结束” 画面. 在训练过程中, 代理在执行此任务时会收到奖励, 称为奖励函数. 通过强化学习, 代理可以非常快速地学习如何超越人类. 缺乏对数据的要求使 RL 成为一种诱人的方法. 然而, 设计一个好的奖励函数是十分困难的, 而且 RL 模型不如监督学习稳定和可预测. 此外, 您需要提供一种方式让代理与游戏交互以产生数据, 这意味着要么构建一个可以与现实世界交互的物理代理, 要么构建一个虚拟代理和一个虚拟世界, 这两者都是具有很大的挑战. 有关 RL 当前面临的问题类型的概述, 请参阅 Alex Irpan 的这篇博文 (opens new window). 强化学习是 ML 研究的一个活跃领域, 但在本课程中, 我们将专注于监督解决方案, 因为它们是一个更广为人知的问题, 更稳定, 并且会产生更简单的系统.
有关 RL 更全面的信息, 请查看 Sutton 和 Barto 的强化学习介绍 (opens new window).
# 常见的机器学习问题类型
根据预测任务的不同, ML 问题有几个子类. 在下表中, 您可以看到常见的有监督和无监督 ML 问题的示例.
| 机器学习问题的类型 | 描述 | 例子 |
|---|---|---|
| 分类 | 从 N 个标签中选择一个 | 猫、狗、马或熊 |
| 回归 | 预测数值 | 点击率 |
| 聚类 | 对类似示例进行分组 | 最相关的内容(无监督) |
| 关联规则学习 | 推断数据中可能的关联模式 | 如果你买汉堡包的面饼, 那你很可能会买整个的汉堡包(无人监督) |
| 结构化输出 | 创建复杂的输出 | 自然语言解析树、图像识别边界框 |
| 排行 | 识别秤或状态上的位置 | 搜索结果排名 |
# 学习成果自测
以下哪个 ML 问题是无监督学习的示例?
- 分类
- 回归
- 结构化输出
- 聚类